



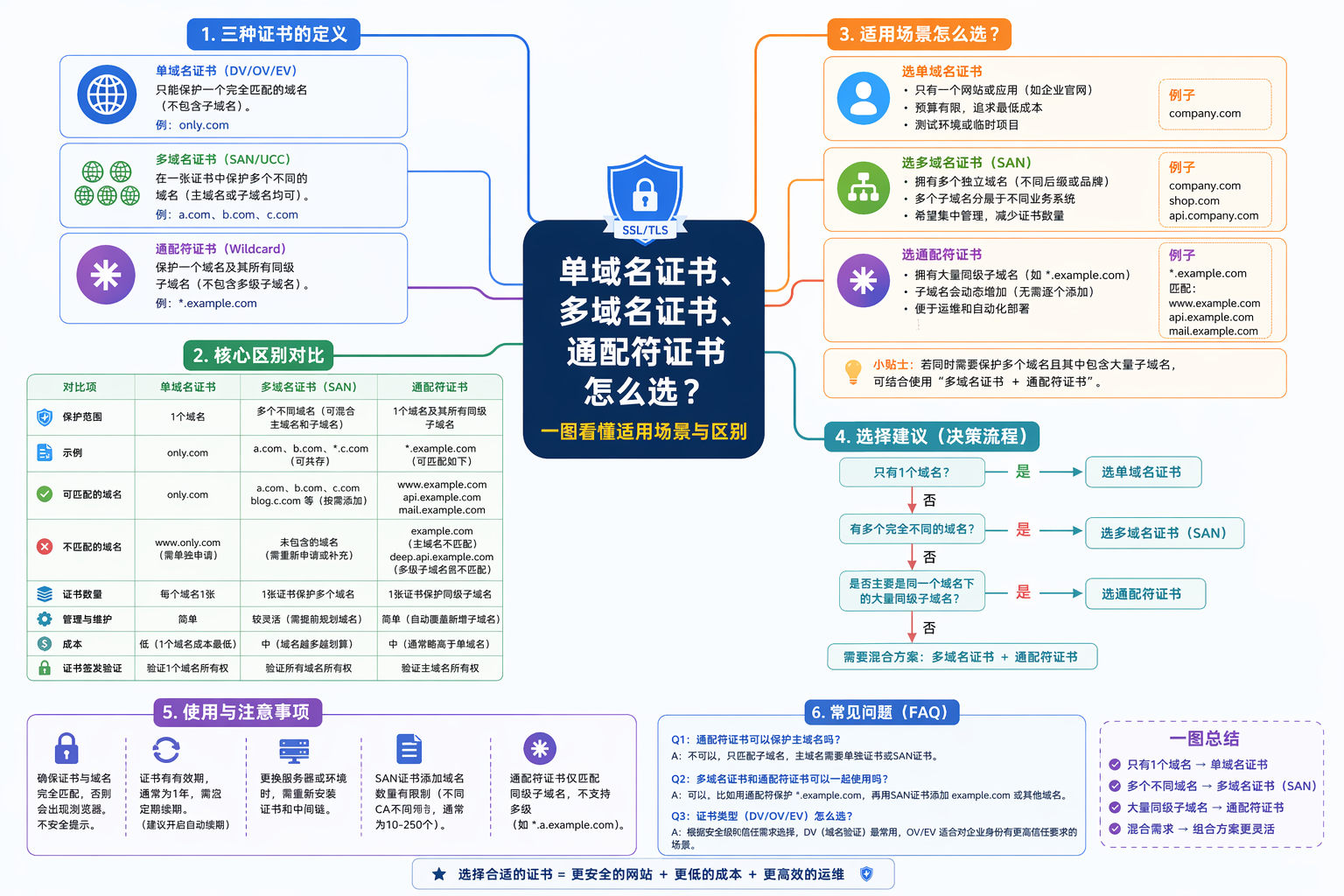
网站除了 sitemap.xml 之外,现在还能通过哪些链接让搜索引擎和 AI 爬虫抓取内容?
如果你想让网站内容更容易被搜索系统发现,或者希望部分 AI 工具在抓取时能更容易读取到网站信息,现在网站已经补充了更多固定的爬虫入口。不再只有原来的 /sitemap.xml 可以使用,爬虫在访问网站时,也可能会继续访问这些新增的路径来获取页面清单和参考信息。
这些新增入口主要包括 /sitemap_index.xml、/sitemap-index.xml、/sitemap1.xml 和 /ai.txt。其中,/sitemap_index.xml 和 /sitemap-index.xml 可以作为补充的站点地图索引入口,/sitemap1.xml 用来承接更具体的页面 URL 清单,方便爬虫继续往下抓取页面内容。

如果你直接访问 /sitemap_index.xml 或 /sitemap-index.xml,页面中会展示站点地图索引内容。这里通常会列出像 /sitemap1.xml 这样的具体 sitemap 文件地址,爬虫会先读取这个索引,再继续进入对应的 sitemap 文件抓取网站页面链接。

如果你访问 /sitemap1.xml,页面中会看到网站的具体 URL 列表,例如首页、语言版本页面或内容详情页等。这个文件的作用就是把站点中的页面地址集中输出,方便搜索引擎和其他爬虫继续识别和抓取这些页面。

另外,网站现在也支持 /ai.txt 这个入口。需要注意的是,/ai.txt 目前还不是像 robots.txt、sitemap.xml 那样已经广泛通用的标准协议,所以它更适合作为提供给部分会主动读取这个路径的 AI 爬虫的参考入口使用,而不是一个必须依赖的标准配置。

如果你在入站访客或抓取记录里看到爬虫访问这些固定链接,一般属于正常现象。因为搜索引擎、AI 工具或其他网络爬虫在发现网站内容时,通常会优先尝试这些常见入口来获取页面索引和站点信息。


















请先 登录后发表评论 ~