




如何通过 robots.txt、服务器日志分析与 URL 参数控制来优化抓取预算 (Crawl Budget),确保核心业务页面优先被抓取?
本文包含AI辅助创作内容
抓取预算(Crawl Budget)是 Googlebot 愿意并且能够分配给特定网站的抓取资源上限。对于结构复杂的系统(如大型营销枢纽、多维度导航站或电商平台),未加干预的爬虫极易迷失在无限的低价值页面中,导致核心业务页面(如新发布的产品页、高转化落地页)迟迟不被收录。
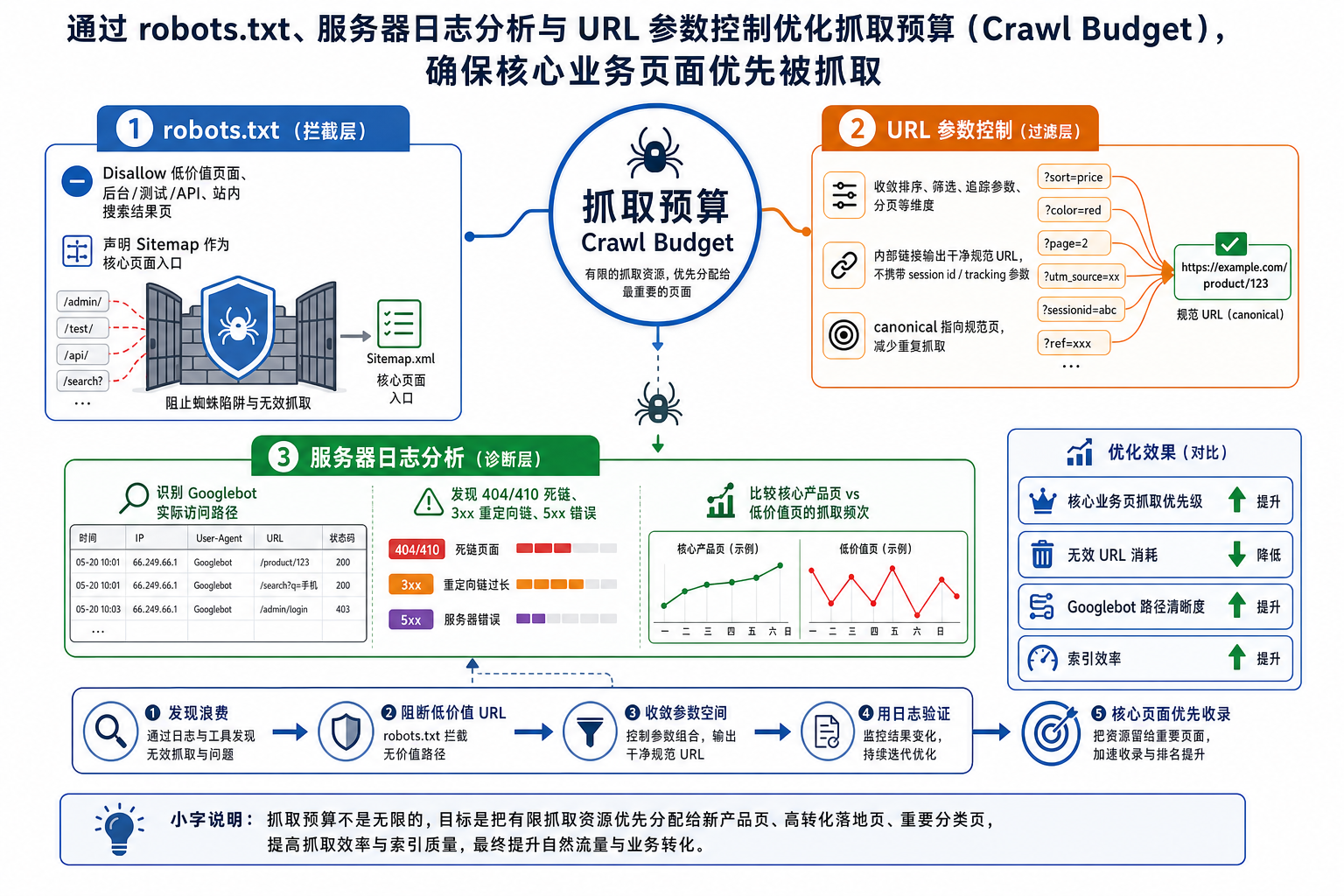
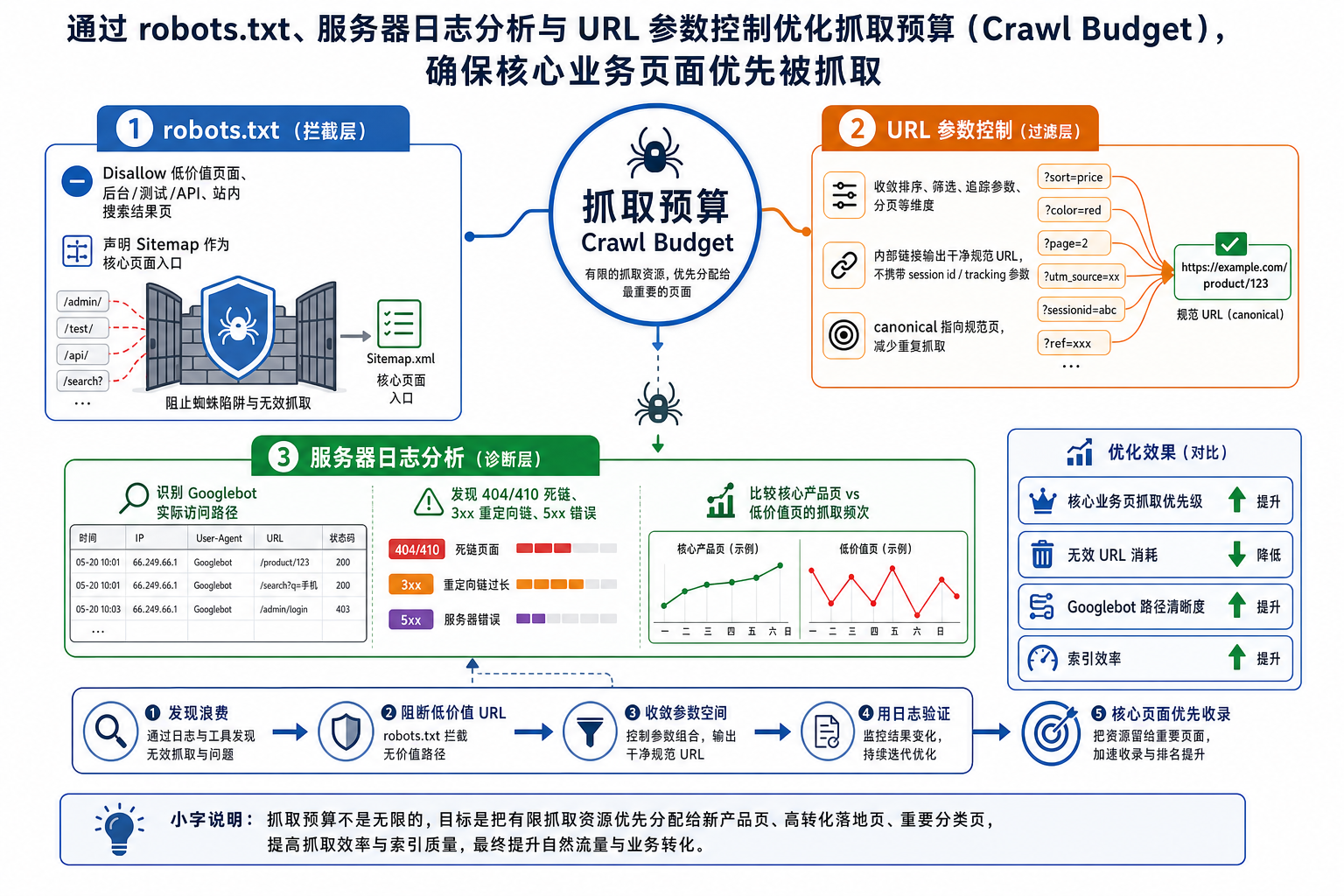
通过 robots.txt、服务器日志分析与 URL 参数控制的“三位一体”策略,可以精确引导爬虫的行动路线。以下是具体的优化逻辑与执行方案:
一、 robots.txt:建立抓取防火墙(拦截层)
robots.txt 是控制抓取预算最直接的工具,它的核心作用是“止损”——直接切断搜索引擎对低价值、非业务相关目录的访问权限。
优化策略:
屏蔽系统级与功能性页面: 后台登录页、测试环境目录、API 接口调用路径、用户私有面板等,这些对自然搜索毫无价值的页面必须全部 Disallow。
屏蔽内部站内搜索结果页 (Site Search): 绝不要让 Google 抓取你的站内搜索结果页。这会导致无限的 URL 变体(所谓的“蜘蛛陷阱”),极其消耗抓取预算。
示例:
Disallow: /search?q=或Disallow: /catalogsearch/
精确指向 Sitemap: 在
robots.txt底部明确声明 XML 地图的绝对路径,相当于直接向爬虫递交核心页面的“白名单导航”。
二、 URL 参数控制:收敛无限的维度(过滤层)
URL 参数(如排序、筛选、追踪、分页)是消耗大型站点抓取预算的“头号杀手”。一个分类页面如果叠加了颜色、尺寸、价格排序,可能会衍生出成百上千个 URL,但核心内容却几乎一致。
优化策略:
利用
robots.txt进行模式匹配拦截: 针对纯粹改变展示状态、不产生新内容的参数(如按价格升降序、按时间排序),直接在robots.txt中使用通配符屏蔽。示例:
Disallow: /*?*sort=或Disallow: /*&order=
规范化内部链接输出: 确保网站系统(前端代码)在生成内部链接时,绝对不要带上追踪参数(如
?source=banner)或 Session ID。系统内部应只流转干净的规范 URL,避免主动向爬虫喂食重复的参数网址。结合
<link rel="canonical">标签: 虽然 Canonical 标签主要是解决“索引重复”问题,但当爬虫长期发现特定参数 URL 都指向同一个规范 URL 时,它也会逐渐降低对这些边缘参数 URL 的抓取频率,从而间接释放抓取预算。
三、 服务器日志分析 (Log File Analysis):穿透盲区(诊断层)
Google Search Console 提供的数据只是抽样,而服务器日志(Nginx/Apache Logs)则是 Googlebot 在你网站上留下的绝对真实且完整的足迹。日志分析是检验上述两步是否有效的唯一标准。
优化策略(通过提取 User-Agent 为 Googlebot 的请求):
排查状态码异常带来的预算浪费:
海量 4xx (404/410): 如果日志显示爬虫每天都在试图访问大量已经删除或失效的页面,说明内部存在大量“死链”。必须清理代码中的陈旧链接。
过多 3xx (重定向链): 爬虫经过 A -> B -> C 的多重跳转会迅速耗尽当前抓取限额。必须将内部链接直接更新为最终目标 URL(即 A -> C)。
5xx (服务器错误): 如果抓取时频繁触发 500 错误,Googlebot 会认为你的服务器负载过高,从而主动“断开连接”并降低未来的抓取频率。
抓取频率与业务权重的错配分析:
对比日志数据:核心产品页面的抓取频次是否远低于某些无关紧要的标签页 (Tags) 或用户评论分页?
如果发现这种“倒挂”现象,说明网站的内部链接架构 (Site Architecture) 存在问题,权重没有顺畅地从首页/频道页流向核心业务页。
标准的优化流程应是:先进行日志分析找出抓取浪费的重灾区 -> 通过 URL 参数控制和代码修复解决死链与蜘蛛陷阱 -> 最终将规则固化到 robots.txt 中 -> 持续监控日志验证效果。















请先 登录后发表评论 ~